Integrated emotion recognition system from multimodal data
October 2022 - June 2024
Information:
- Type: Academic project
- Link: CLICK
- Technologies: Python Scikit-Learn PyTorch Audiomentations Librosa
Summary:
Description:
Human beings express and perceive their emotions in a multimodal manner, with a multimodal approach being essential for the development of artificial intelligence systems capable of interacting with people based on emotions. Such a system can be used in numerous applications, from monitoring behavioral and emotional disorders to public safety.
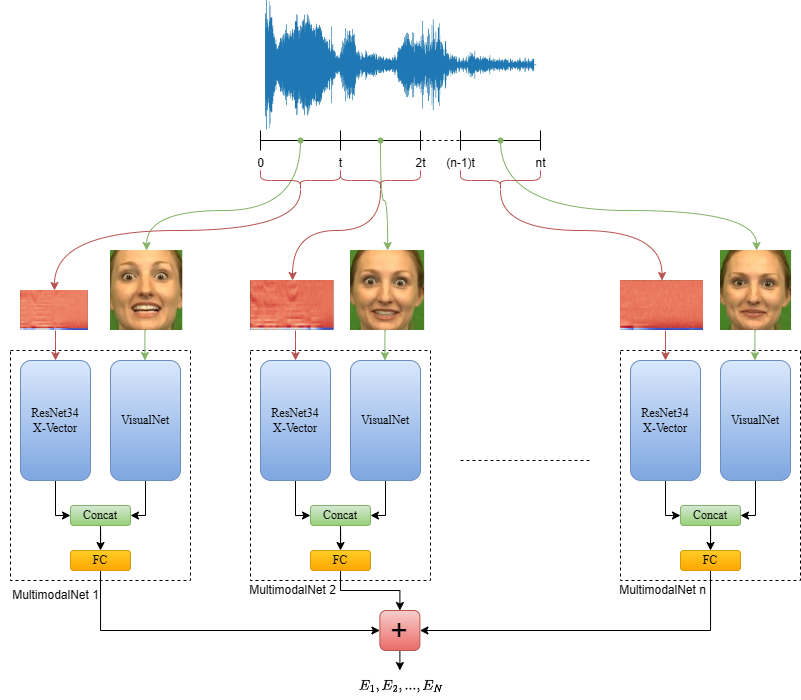
In this thesis, a multimodal system was developed to recognize emotions using both audio and visual information from video sequences. The system can interpret emotions from audio signals and images, employing a window-based approach for the audio signal and a limited number of frames extracted from the video.
The ResNet architecture, enhanced with an x-vector based on the self-attention mechanism, was used to recognize emotions from audio signals, processing data in the form of Mel-frequency cepstral coefficients (MFCC). For emotion recognition from images, a convolutional neural network was developed to process visual frames containing human faces detected using the MTCNN model. Data fusion was achieved by combining audio and visual information from several temporal segments.
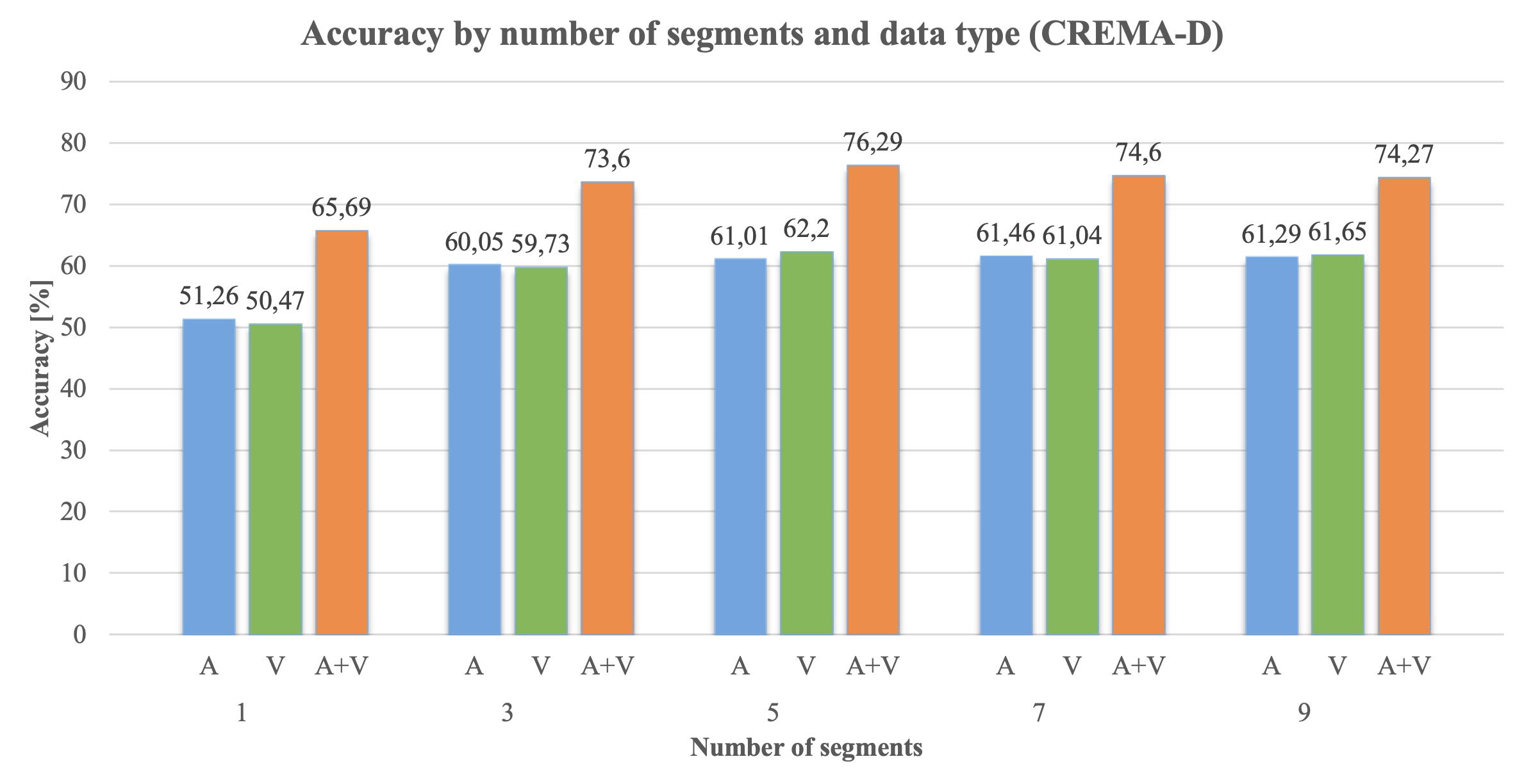
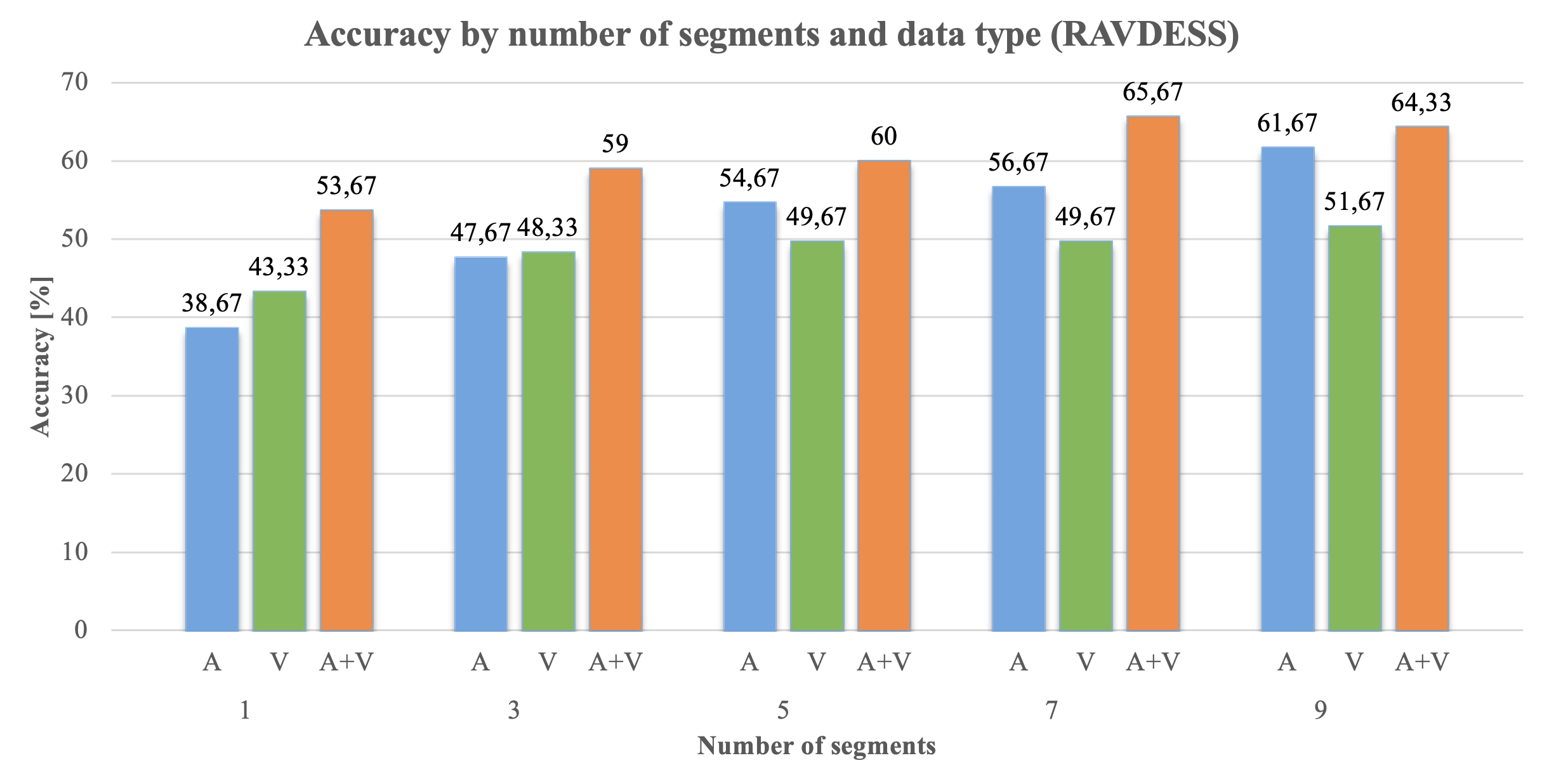
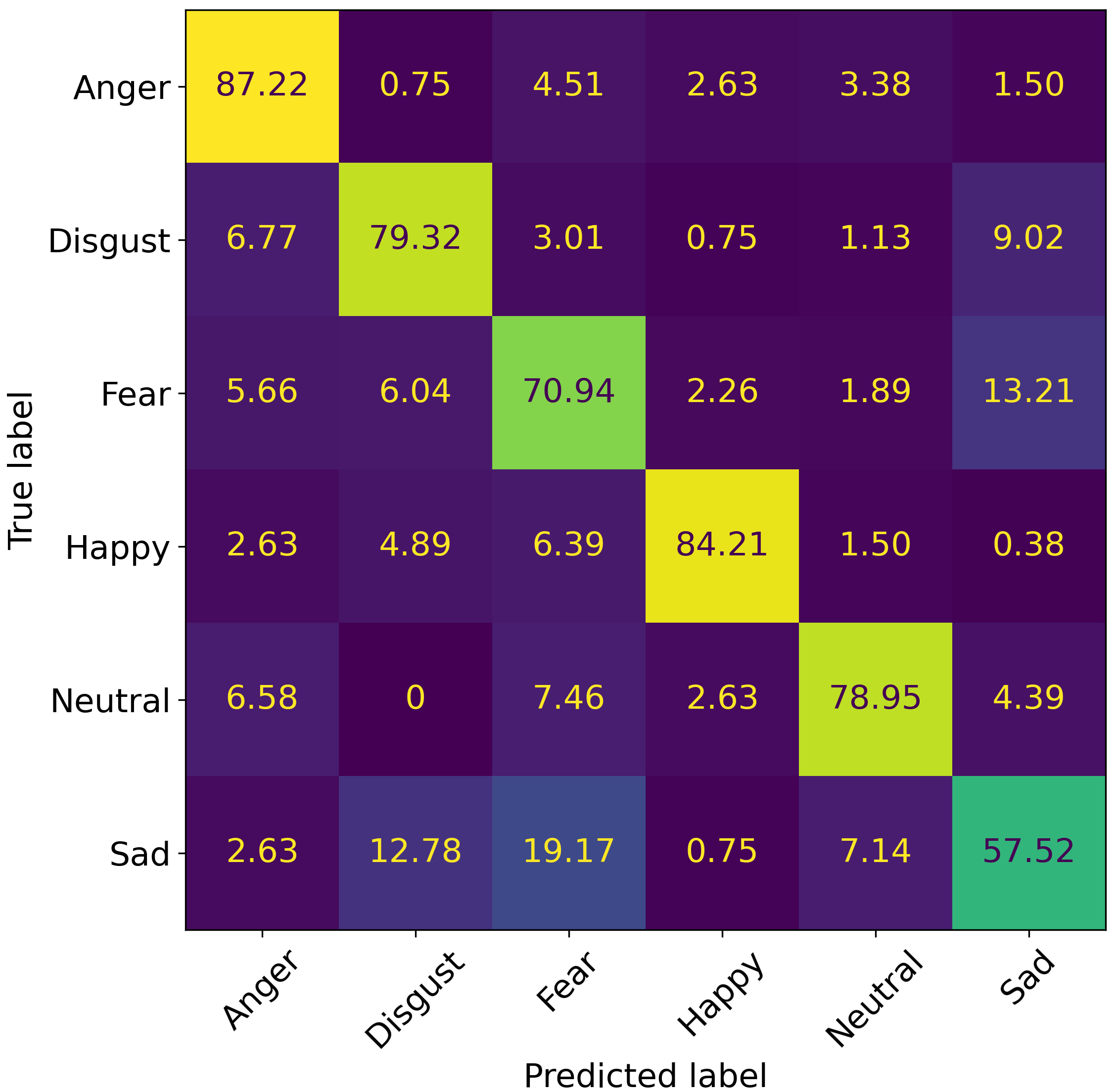
The system was trained on the CREMA-D and RAVDESS datasets, with experiments demonstrating competitive performance. For the CREMA-D dataset, the overall accuracy reached 63.05% for audio, 64.09% for visual, and 76.29% for multimodal data, while for the RAVDESS dataset, the overall accuracy reached 62% for audio, 55.67% for visual, and 65.67% for multimodal data.
Furthermore, the thesis highlights the importance of finding an optimal number of segments, as a large number of segments increases the model's response time without significantly improving performance.
To explore the possibility of providing an integrated solution for emotion recognition, the neural model with the best performance was successfully integrated on the NVIDIA Jetson Nano development board for inference tasks.